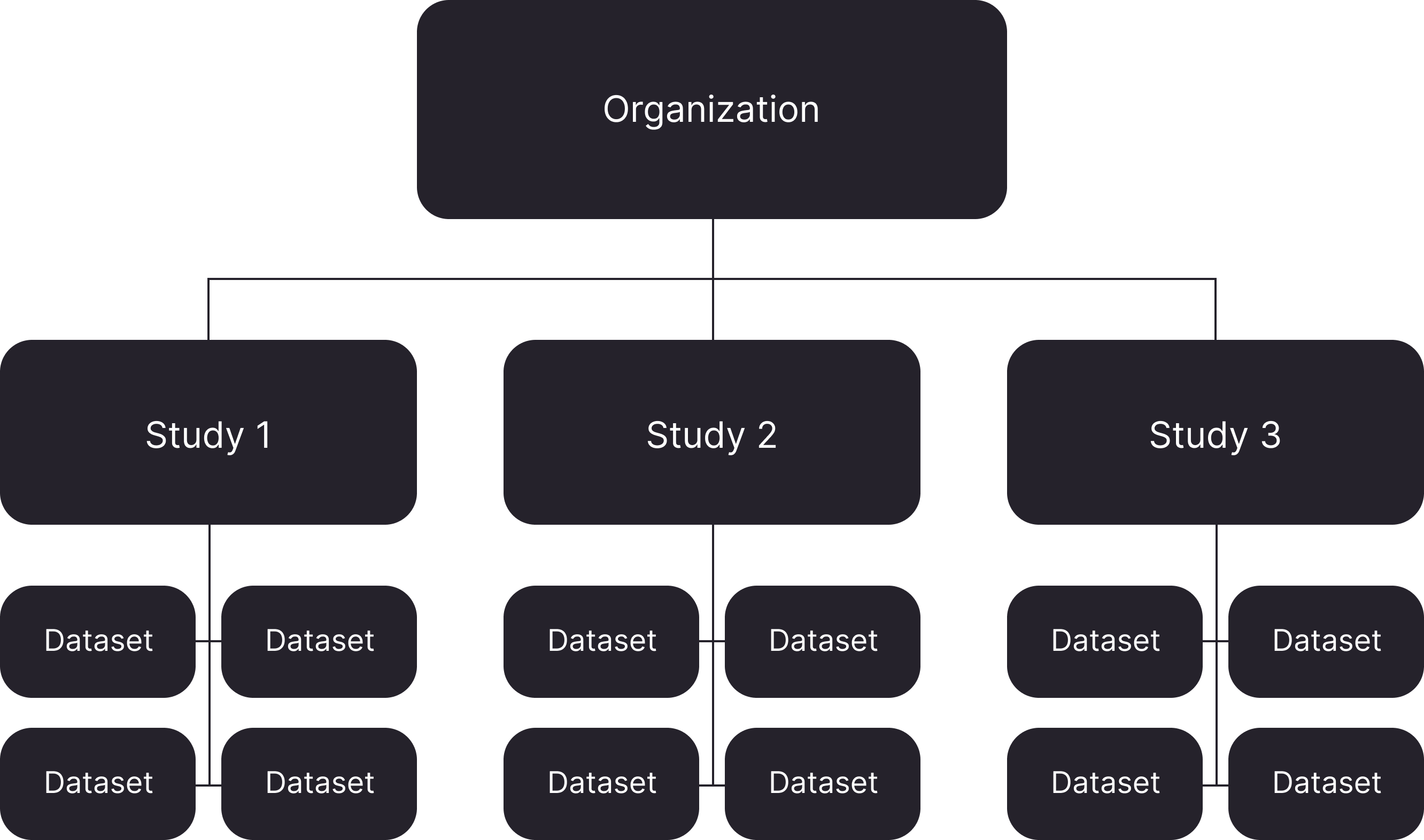
The list and visualization below illustrate how a Kernel Cloud Organization and its research are organized in the Kernel Cloud database.
- DATASET: an individual collection of data, such as a Kernel Flow recording (e.g. what is captured between Record start and Record stop of the Flow system). Datasets can also refer to data collected through a survey or other data stream. A dataset has a variety of metadata saved with it.
- SESSION: a collection of individual datasets, such as all the datasets recorded while a participant is wearing the headset on a specific day.
- STUDY: a research project. May include multiple tasks, and research may be conducted over many sessions with many participants.
- TASK: an individual experiment within a study.
An Organization can have an unlimited number of Studies, each Study can have an unlimited number of sessions, and each session can have an unlimited number of datasets. Datasets can optionally be associated with a Task name.